
Els models de llenguatge han evolucionat significativament en els darrers anys, i una de les claus d’aquesta evolució és el procés de post-entrenament.
Tradicionalment, aquest refinament s’ha dut a terme en models de propietat tancada com InstructGPT, combinant ajustaments d’instruccions i optimització de preferències. No obstant això, aquest procés té el repte d’afegir noves habilitats sense comprometre altres capacitats generals. En aquest context, Tülu 3 emergeix com una proposta disruptiva: un model de codi obert que no només tanca la bretxa amb les alternatives comercials, sinó que també ofereix total transparència en el seu procés d’entrenament i refinament.
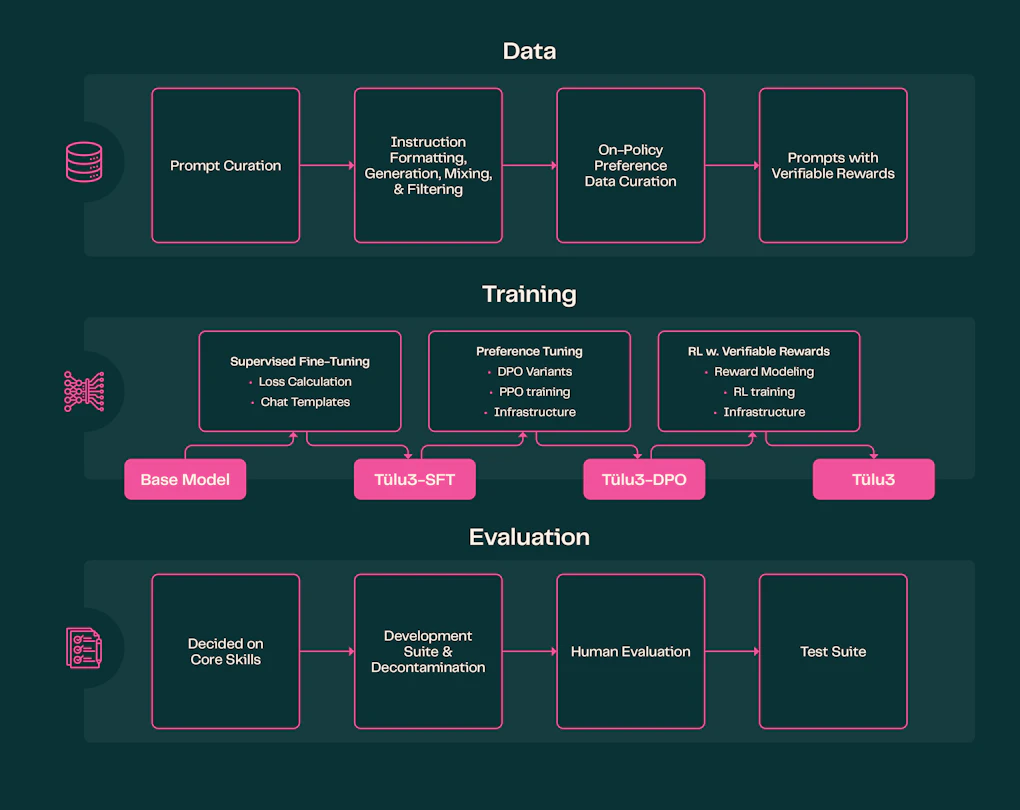
Post-Entrenament Transparent: Un Pas Endavant per a la Comunitat IA
Fins ara, els models d’intel·ligència artificial més avançats han seguit estratègies sofisticades de post-entrenament, combinant dades sintètiques i ajustaments en múltiples fases. El problema és que les metodologies exactes i els conjunts de dades utilitzats han estat propietat exclusiva d’empreses com OpenAI, Anthropic o Google, sense compartir informació amb la comunitat.
Això ha limitat el desenvolupament de models de codi obert, ja que els investigadors no han tingut accés a dades fonamentals per replicar i millorar aquests processos. De fet, fins al novembre de 2024, cap dels 50 millors models en LMSYS’s ChatBotArena havia publicat detalls sobre el seu post-entrenament.
Aquí és on Tülu 3 marca la diferència. Aquest model no només arriba a nivells competitius en tasques complexes, sinó que també fa públics tots els aspectes del seu entrenament: des de les dades utilitzades fins a les tècniques aplicades per refinar la seva capacitat d’interpretació i resposta. Aquesta transparència representa una fita important per a la recerca en IA i obre noves possibilitats per a la comunitat.
Innovació en Aprenentatge per Reforç: La Revolució del RLVR
Un dels elements més destacats de Tülu 3 és la incorporació del Reinforcement Learning with Verifiable Rewards (RLVR), una tècnica d’aprenentatge per reforç basada en recompenses verificables.
A diferència dels enfocaments tradicionals, que depenen de models de recompensa subjectius, RLVR es basa en criteris objectius i mesurables. Això significa que el model aprèn a partir de resultats concrets: una operació matemàtica és correcta o incorrecta, un fragment de codi s’executa o presenta errors.
Aquest enfocament elimina les ambigüitats inherents als sistemes de recompensa convencionals i millora la capacitat del model per resoldre problemes tècnics amb precisió. En les nostres proves, Tülu 3 ha mostrat una excel·lent capacitat per gestionar tasques de matemàtiques avançades i programació, consolidant-se com una eina poderosa per a desenvolupadors i investigadors.
Eficiència en la Generació de Respostes: Optimització de Preferències Directes
Un altre repte habitual en el post-entrenament és que els models tendeixen a generar respostes innecessàriament llargues per tal de maximitzar la seva puntuació de preferència. Allen AI ha abordat aquest problema mitjançant l’Optimització de Preferències Directes (DPO) normalitzada per longitud, una tècnica que ens ha sorprès gratament.
Aquest mètode permet a Tülu 3 generar respostes concises i precises sense sacrificar informació essencial. Això es tradueix en una millora substancial en la qualitat del text generat, fent que les respostes siguin més útils i eficients en la comunicació.
Tülu 3 vs. Models Tancats: Una Alternativa Competitiva
L’experiència amb Tülu 3 ens ha permès veure que aquest model de codi obert no només està a l’altura dels millors models tancats del mercat, sinó que també aporta una nova dimensió a la investigació en IA.
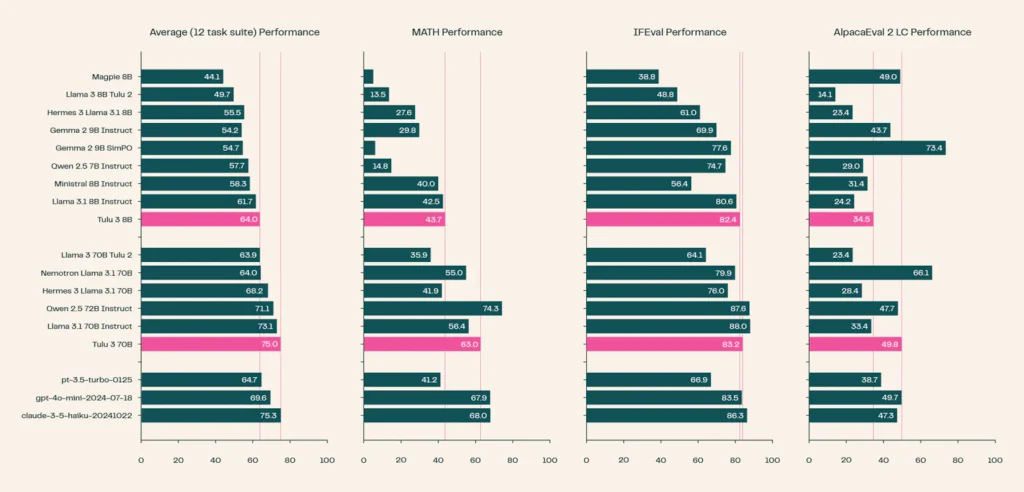
La seva capacitat per igualar models comercials en àmbits com el raonament, la programació i el seguiment d’instruccions demostra que l’era de la IA avançada ja no és exclusiva de les grans corporacions. A més, el fet que Allen AI hagi fet públics tots els detalls del seu entrenament suposa una revolució en la manera com es desenvolupen els models de llenguatge.
El Futur de la IA Oberta: Un Model per Seguir de Prop
Tülu 3 representa un punt d’inflexió per als models de llenguatge de codi obert. La combinació d’una arquitectura robusta, un post-entrenament transparent i una estratègia innovadora d’aprenentatge per reforç el converteixen en una opció que cal seguir de prop.
L’aposta per l’obertura i la documentació detallada permetrà que investigadors i desenvolupadors puguin explorar noves vies d’optimització i adaptació del model a diferents àmbits. Sens dubte, estem davant d’una eina prometedora que podria redefinir el futur de la IA accessible i col·laborativa.




